Visualizing Packrat Parsing
January 10, 2021Ohm is an open-source parsing toolkit for JavaScript which Alex Warth and I have been working on since 2014. You can use it to parse custom file formats or quickly build parsers, interpreters, and compilers for programming languages.
This article is not about Ohm itself, but about the Ohm visualizer, which I designed and built in 2015 while working on Alex’s team at CDG.1 Later, the team expanded the visualizer into the Ohm Editor, which we continued to actively develop over the years. The editor itself has been presented before, so I’ll focus specifically on the visualization here.
Creating the visualization was one of the most difficult and interesting design challenges I’ve ever tackled — so it’s been rewarding to hear from people who have found it to be helpful:
Hey, I used Ohm for the first time a couple days ago.
— Anselm Eickhoff (@ae_play) January 7, 2021
I used to have an irrational fear of writing parsers.
Your visualization cured it.
Thanks a lot!
The Problem
Ohm is based on parsing expression grammars (PEGs), which are a formal way of describing syntax, similar to regular expressions and context-free grammars. Like other PEG-based tools, it uses packrat parsing, a form of top-down parsing with unlimited lookahead.
One of Ohm’s main goals is ease-of-use — not only for the end users of languages, but also for grammar authors. And debugging grammars can be a notoriously painful. So I designed and built an interactive visualization that makes the entire execution of the parser visible and tangible. This lets grammar authors follow the flow2 rather than “playing computer” and trying to simulate the execution in their head.
When creating or debugging a grammar, there are a few things you might be interested in:
- If the parse succeeded…
- …what does the parse tree look like?
- Did it parse the input the way I intended? If not, why not?
- If the parse failed, why did it fail?
Initially, I explored two different design directions: one focused on the output (the parse tree), and another that focused on the algorithm execution. The big challenge was to come up with a design that could do both.
Note: You can try out all the examples here online in the Ohm Editor.
Visualizing Parse Trees
To visualize the parse tree, I chose a variant of the icicle plot (Kruskal and Landwehr 1983). Some people may be more familiar with the flame graphs used in software profilers, which are basically inverted icicle plots.
Each node is represented by a gray rectangle, with its children directly below it. A dashed bottom border indicates a node with hidden children. You can click on a node to show or hide its children.
Unlike most icicle plots, the absolute width of a box is not meaningful — only its width and position relative to the input text. Nodes always sit directly below the input text they consumed.3 This is emphasized by highlighting the relevant portion of the input when the cursor is over the node:
This means that the node must be at least as wide as its consumed input. We also ensure that the nodes are always wide enough to display the full label. So unlike most hierarchicial visualizations, there’s no need to hover over a node to see its label.
To satisfy both of these width constraints, the layout algorithm will expand the letter spacing of the input text where required:

(click to replay)
Visualizing the parser execution
A parse tree visualization can help you understand what the parse tree looks like, but only if the parse succeeded. If the input failed to parse, or if the parse tree is not what you intended, you’ll want to understand why.
To answer this question, I designed the “explain parse” feature, which shows a visual explanation of the parser’s execution. This can be enabled via the option panel in the lower right corner:
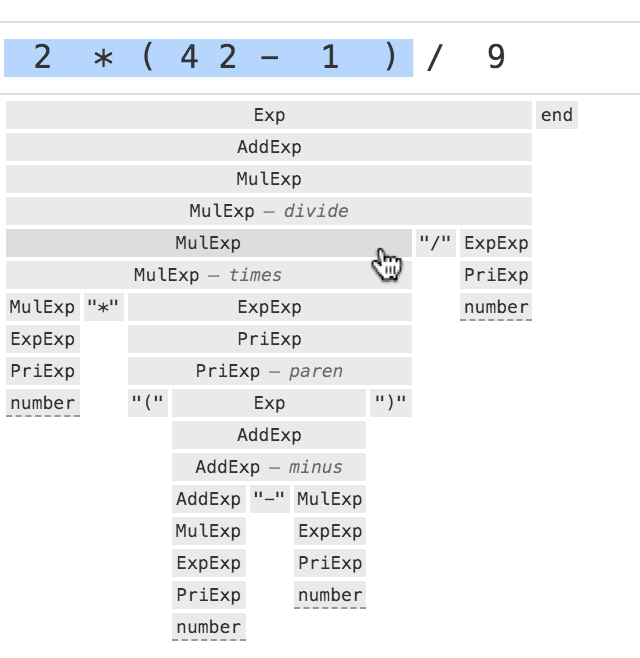
Like other PEG-based tools, Ohm uses recursive-descent parsing. A useful property of recursive-descent parsing is that parser’s execution (e.g. as represented by a dynamic call graph) has a very similar structure to the parse tree. This made it possible to design a single visualization that serves both purposes.
Let’s take a simple grammar for parsing credit card expiry dates. The animation below shows a trace of the logical steps taken to parse the input “08/24”.
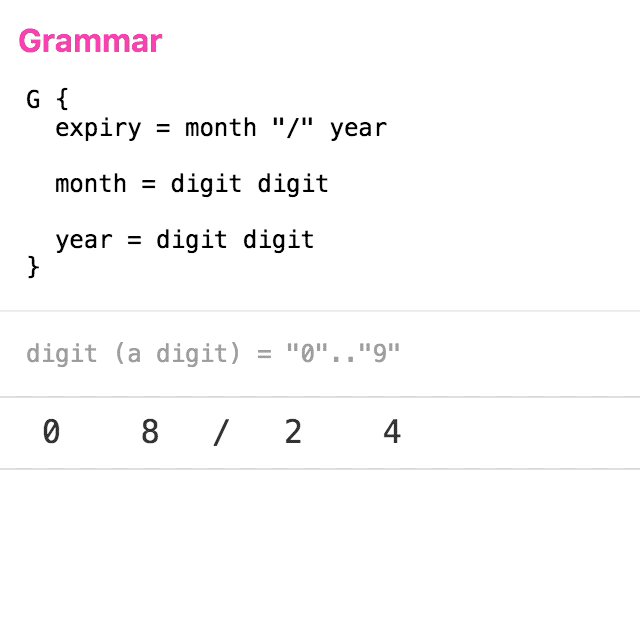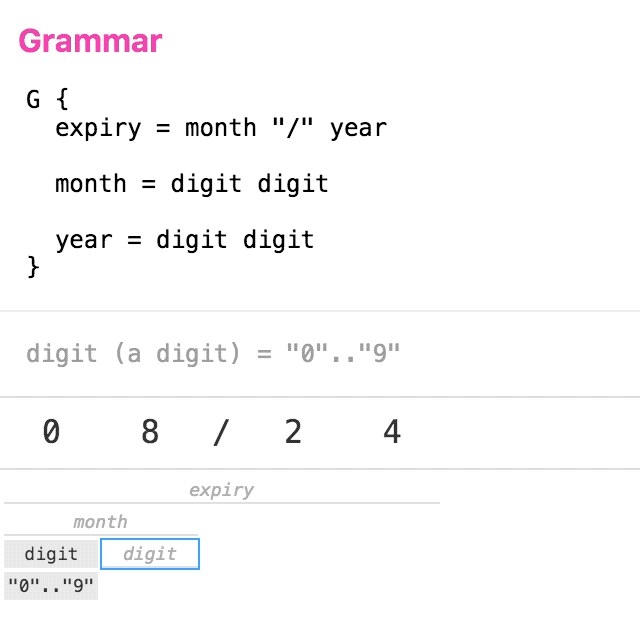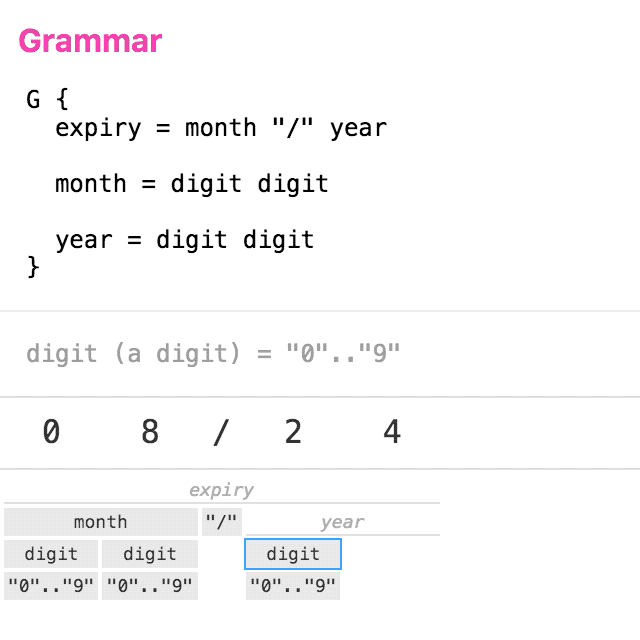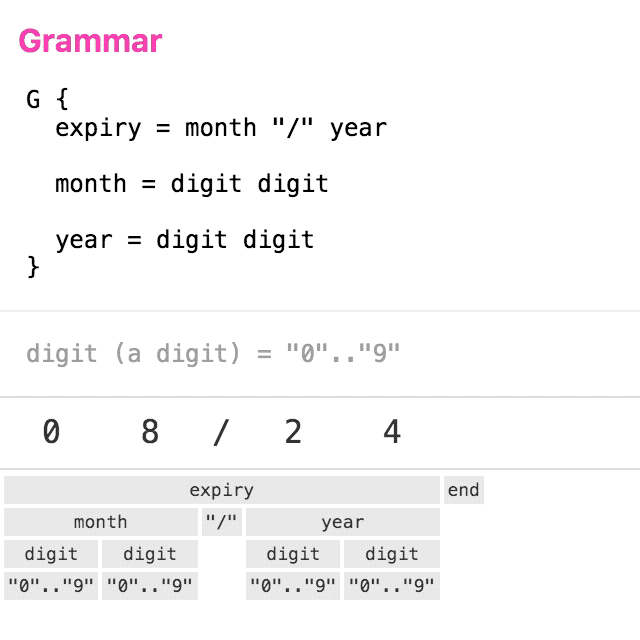
(click to replay)
You can see that the tree is built in a top-down, left-to-right manner. Each non-leaf node is visited twice: once on the way down, and again on the way up. This is the basic structure of recursive-descent parsing.
In this extremely simple example, every step taken by the parser succeeds. So the execution trace looks exactly like the parse tree. This is not usually the case. Let’s take a look at a more complex example:
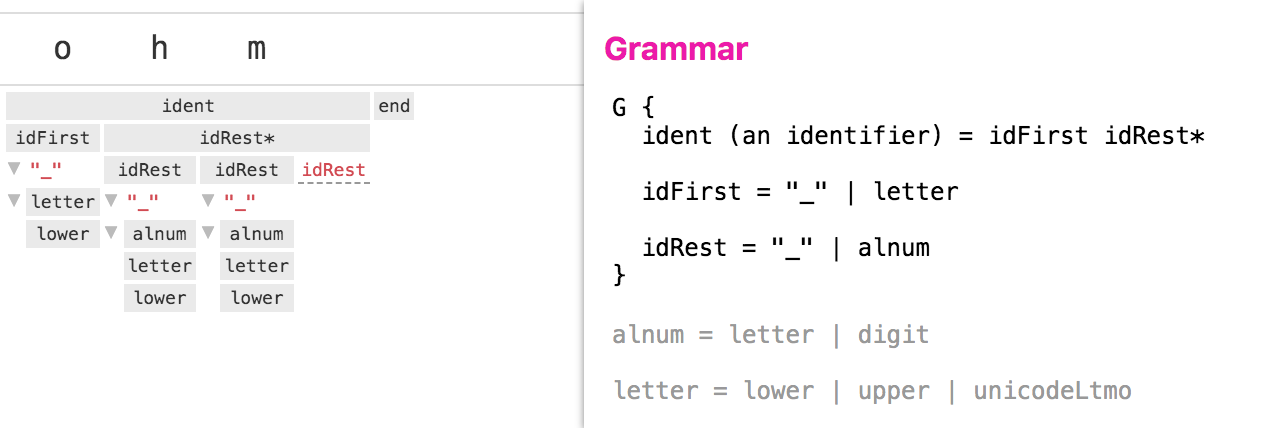
In this example, several steps in the parsing failed to match any input (shown with red labels). This doesn’t mean something went wrong — this is just part of the way that a packrat parser works. The screenshot above shows two different types of match failure that can happen:
- Failed branches of an alternation expression, as seen under
idFirst. The parser first attempts to match an underscore ("_"), which fails, before successfully matchingletteron the second branch. - The last child of an repetition expression. The repetition expression
idRest*means to matchidRestas many times as possible; the last attempt will always fail by definition.

Backtracking
Another challenge in designing the visualization was how to deal with backtracking. In a packrat parser, backtracking happens when a successful match is part of a larger expression which fails.
For example, many programming languages contain keywords (e.g. function) which can appear in the same position as a variable name. A common way to handle this is to use negative lookahead to prevent incorrectly matching a keyword at the beginning of an identifier like “functional”.
Here is the same grammar from before, modified to include a functionKeyword rule. And here is the visual explanation of matching the the input “functional”:
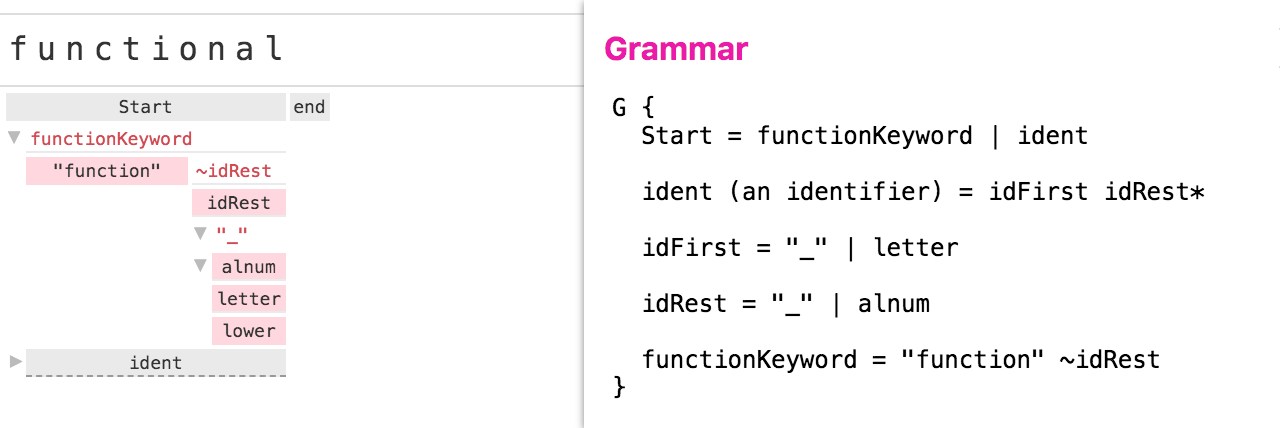
The nodes with a pink background are nodes which successfully matched some portion of the input, but were ultimately discarded during backtracking.
Left recursion
One thing in Ohm that’s different from many similar tools is its special support for left recursion. The arithmetic grammar included in the Ohm Editor has some examples of left-recursive rules:
AddExp
= AddExp "+" MulExp -- plus
| AddExp "-" MulExp -- minus
| MulExpNotice that the first two branches of AddExp begin with a recursive application of AddExp itself — that’s left recursion. In a typical recursive-descent parser, this would result in infinite recursion. However, since it’s so convenient to define left-associative operators this way, the Ohm parsing algorithm detects these rules and handles them specially.4
Ohm handles left recursion by iteratively trying to expand the input consumed by the left-recursive rule, and stopping when it can’t be expanded any further. As a grammar author, you might sometimes wonder why it stopped when it did. To find out, you can look at the special [Grow LR] node that appears as the last child of any left-recursive rule application:
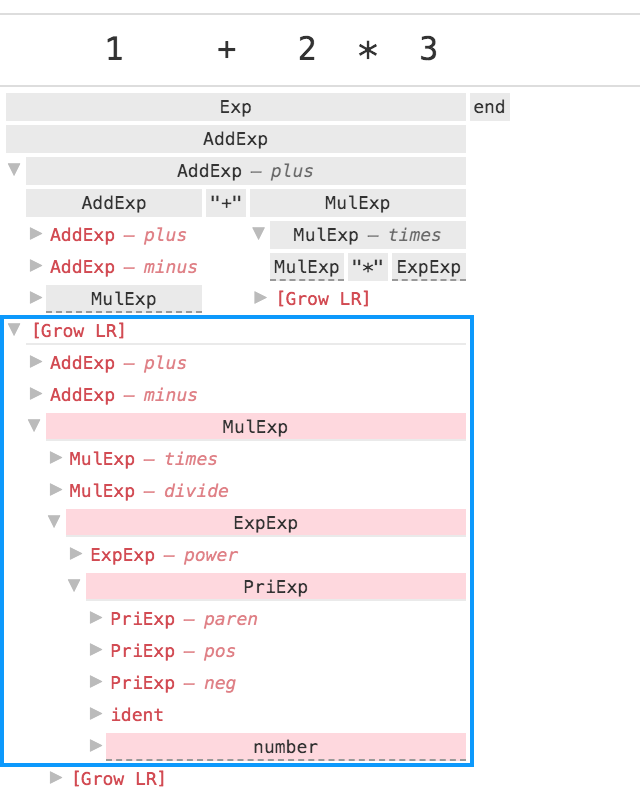
Single-stepping
One other feature of the visual parse explanation is the ability to single-step through the parser’s execution. In terms of information content, it doesn’t show anything that’s not already visible in the full visualization — so in a sense, it’s not strictly necessary. However, I hoped that it might help new users learn how the visualization works.
Single-stepping can be controlled through the buttons in the option panel:
You can also right-click on any node and choose “step into” or “step out”:
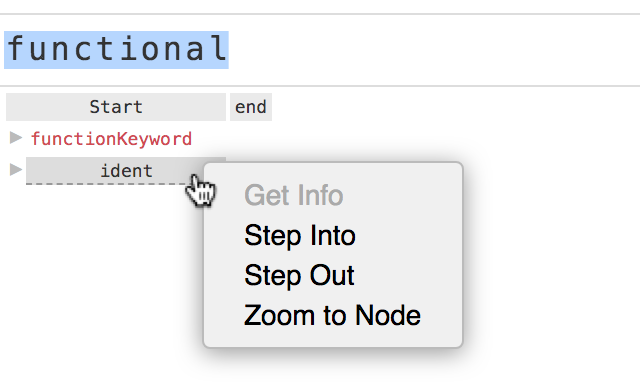
From there, you can use the arrow keys to step forwards (→) or backwards (←) through the logical steps of the parser execution:

(click to replay)
As I explained at the beginning, my goal with the Ohm visualizer was to make entire execution of the parser visible and tangible. In the end, I think I was able to achieve that — but I’m sure there are also many aspects of the design that could be improved. If you have ideas, please feel free to get in touch!
Further Reading
Here are some links if you are interested in learning more about the Ohm Editor or Ohm itself:
- Ohm project page
- Github repo for the Ohm Editor. PRs and bug reports are always welcome! 🙂
- Language Hacking in a Live Programming Environment is a web essay where we presented an earlier version of the Ohm Editor.
-
CDG (later known as HARC) was a short-lived research organization, founded by Alan Kay, where worked from 2014-2017. See my post Sketches from CDG for more. ↩
-
"Follow the flow" is one of the principles from our colleague Bret Victor's essay Learnable Programming. ↩
-
Legible Mathematics (2014) by Glen Chiacchieri was an inspiration here. Glen also contributed important feedback and ideas early in the design process. ↩
-
The full details are beyond the scope of this article, but see the paper Packrat parsers can support left recursion for more details. ↩